Falsches digitales Rechtsbewusstsein (Teil 2)
Falsches digitales Rechtsbewusstsein – Legaltech als «delirium digitalis» (Teil 2)⌗
Die Stimme der Vernunft ist leise. Siegmund Freud
Einordnung⌗
Die trotz der Materialfülle und einiger lucidum intervallum offenkundige logisch lückenhafte und erratische «Argumentation» von Adrian falsifiziert unerwartet deutlich die Eingangstehen des Autors:
- Es gibt doch (juristische) Semantik!
- Es kann nach dieser «Logik» keinen Richterautomaten!
Welchen weiteren fehlerhaften Grundannahmen und Irrtümern unterliegt Adrian?
Das Ende des linguistic turn?⌗
Wie schon in Teil 1 angemerkt, wird die im Titel behauptete These, «Semantik sei eine Illusion», von Adrian nur mit Verweis auf den frühen Wittgenstein und den linguistic turn begründet, freilich ohne die spätere Sicht von Wittgenstein zu berücksichtigen und ohne den linguistic turn entsprechend einzuordnen (vgl. z. B. Das Ende des linguistic turn?).
Diese These wird nicht nur nicht erhärtet, sondern im Gegenteil laufend apodiktisch als Argument und Dogma eingebracht und in Übereinstimmung mit dem funktionalistischen KI-Ansatz und der Ideologie des Digitalismus.
Funktionalismus und Digitalismus⌗
Ein Hauptproblem des ganzen Aufsatzes ist, dass Adrian nur gesprochene oder geschriebene sprachliche Äusserungen überhaupt gelten lässt. Auch mit «Sprachquanten» meint er lediglich juristische «Textartefakte». Wenn Adrian auf juristische Texte oder explizite Sprechakte als Intelligenzsubstrate fokussiert, so geht er – auch wenn er sich am Anfang als Idealisten und Anti-Empiristen bezeichnet – implizit von einem rein materialistischen Erkenntnisbild aus, das geistiges ausklammert.
Gedanken als reale mentale Zustände physischer Systeme und als intelligente Bedeutungsträger werden von Adrian nicht behandelt. Dass Jurist*innen denken können und sich darüber intersubjektiv austauschen können, verkennt er.
Adrian erkennt zwar an, dass Sprache und deren Verwendung gelernt wird (S 88ff). Jeder Mensch erhalte so ein “holistisches Netz”, das ihn oder sie individuell auszeichne.
Kommunikation erlaube aber nur den Austausch von Worten und Zeichen (als Syntax), «deren semantische Bedeutung aus prinzipiellen Gründen […] nicht geklärt werden» könne. Es sei deshalb (S 91) «hilfreich, zu erkennen, dass man aus prinzipiellen, philosophischen Gründen gar nicht verstanden werden» könne (Hervorhebung PE).
Die «Idee einer semantischen Bedeutung der natürlichen Sprache» sei «nur eine Illusion der Menschen […]. Menschen simulieren also nur, dass die natürliche Sprache eine semantische Bedeutung hätte».
Zu behaupten, dass Menschen nur simulieren, dass Sprache für sie Bedeutung hätte, widerspricht diametral der psychischen Realität und der Eigenwahrnehmung aller Menschen1.
Adrian schliesst hier aus der Tatsache, dass Symbole (als Zeichen, im Unterschied zu Indizes und Ikonen) arbiträr gesetzt und benutzt werden, dass sie keine Bedeutung hätten. Er bringt dafür Quines Beispiel, bei dem jemand auf ein vorbeilaufende Kaninchen weist und “Gavagai” sagt (S 89).
Natürlich funktioniert sprachliche Kommunikation semantisch, aber nur wenn die Begriffe mit Erfahrung verknüpft sind. Wenn jemand in der geschilderten Situation «Kaninchen» sagen würde, sähe die Sache ja schon verständlicher aus, weil eben Semantik dazu kommt. Deshalb lernt man Sprachen und studiert Rechtswissenschaften. Das ist so banal, dass es fast schwer fällt, darauf hinzuweisen.
Selbst die kontextuelle Bezugnahme von Sprechakten zur inferentiellen Generierung von Semantik nach Brandom (S 91) lehnt Adrian nach der Anmerkung, dass diese Theorie «viel komplexer und komplizierter ist, als dies hier dargestellt werden kann» mit dem erneuten axiomatischen Hinweis ab, «Es ist den Menschen aus prinzipiellen Gründen […] nicht möglich, semantische Bedeutung auszutauschen».
Adrian liegt hier nicht nur aus der Sicht des gewöhnlichen Hausverstands falsch:
-
Menschen wissen sehr präzise, ob sie etwas verstanden haben und verstanden worden sind. Menschen kommunizieren in der Regel genau deshalb, um Bedeutung und Sinn auszutauschen – selbst wenn es nur um das Verstehen eines Witzes geht. Niemand würde sagen, dass ein guter Witz keinerlei Bedeutung (Semantik) hat. Und jeder weiss, ob ersie die Pointe verstanden hat oder nicht.
-
In philosophischer Hinsicht können Gedanken als mentale Zustände mit bestimmten (Bedeutungs-)Qualitäten verstanden werden. Gedanken könne sich auf Tatsachen des Universums/der Natur beziehen («Die Sonne scheint.») oder auf Tatsachen der Rechtssphäre («Mietrecht existiert») oder auf andere Gedanken (z. B. auf Absichten «Ich muss noch den Gewährleistungsanspruch prüfen.»).
-
Semantisch und inhaltlich verstanden beweist unser juristisches System tagtäglich, dass sich Jurist*innen über juristische Sachverhalte und Begriffe austauschen können und dass sie sich über das schuldhafte an der Schuld oder das kontokorrentmässige am Kontokorrentkredit verständigen können. Eine objektivierte Rechtsphänomenologie ist wegen der nicht nur subjektiven sondern auch propositionalen Qualität von Ideen möglich. Sie wird auch von der Rechtswissenschaft seit Jahrhunderten kultiviert und gelebt.
-
Indem Adrian nur auf Sprachartefakte als materialisiertes Ergebnis juristischer Denktätigkeit abstellt und diese wie eine Nebelgranate als «Sprachquanten» bezeichnet, folgt er im Grunde einem panpsychischen Ansatz. Nach diesen wird die (ungeistige) Natur mit Geist aufgeladen: Materie ist demnach das aktuelle lokale Ergebnis einer grossen Berechnung die live abläuft. Nach Adrian sind die juristischen Schrifstücke als Sprachquanten die in die Materie internalisierten panpsychischen Denkprozesse.
Das schreibt er zwar nicht, aber nur so kann man das von ihm behauptete Ergebnis überhaupt erklärbar machen. (Die Frage, ob es sinnvoll ist, hier noch etwas erklärbar machen und retten zu wollen, einmal aussen vor gelassen.)
Bei Adrian sind es juristische Texte, die als Sprachquanten gedanklich mit Geist beseelt werden und über deren maschinenverarbeitete syntaktische Simulation juristische Expertise aus der Maschine kommen soll.
Da «in den Rechtswissenschaften keine Einigkeit darin» bestehe «wie der juristische Entscheider die semantische Bedeutung korrekt aus dem Text „herauszuholen“» (S 83) habe und wegen der (nicht belastbaren) Hinweise auf Wittgenstein und den linguistic turn ignoriert Adrian das geistvolle der juristischen Tätigkeit und des juristischen Sachverstands und verschiebt es – wie in einem Taschenspielertrick – in die physische Realität der Texte als “Sprachquanten”, um es von dort als deus-ex-machine glorios wieder hervorzuholen und es als Theorie der Möglichkeit eines Richterautomaten auferstehen zu lassen.
Adrian übersieht dabei, dass juristische Schriftartefakte lediglich das Ergebnis einer geistigen juristischen Tätigkeit sind und nicht deren Quelle.
Trotz dieses überzogenen Ansatzes ist Adrian klar, dass seine Maschine – übrigens wegen prinzipieller sozialer und kontextbezogener Blindheit und Inkompetenz von künstlicher Intelligenz Maschinenlernen – sehr viel menschliche Semantik im Vorlauf benötigt und dass «menschliche Juristen» weiter erforderlich bleiben, um die Maschine quasi zu füttern (S 105). Er sieht weiters ein, dass «unsere Maschine […] ihre Stärke in der Klärung rechtlicher Fragen und nicht in der Erstellung des rechtlich relevanten Sachverhaltes» hätte.
Das ist vollkommen richtig, ein erneutes lucidum intervallum: Warum das aber so ist, dass Menschen das beherrschen wenn sie Semantik doch nur simulieren, bleibt im Dunkeln.
Der semantikfreie Richterautomat würde also, selbst nach Adrian, nur funktionieren, wenn er mit möglichst viel menschlicher Semantik aufgeladen und mit mit juristischem Verstand vorsortierten Inhalten gefüttert werden würde.
Unterkomplexität künstlicher Intelligenz von Maschinenlernen⌗
Adrian geht auf die Frage nicht ein, nach welchen Algorithmen dieser Richterautomat eine juristische Bedeutung mit konkretem Bezug auf einen Rechtsfall aus den «Textquanten» herausholen können soll. Wäre er der Frage nachgegangen, so hätte er erkennen müssen, dass künstliche Intelligenz Maschinenlernen lediglich eine Denkausführung nach einem vordefinierten formalen Schema und mit Bezug auf ein im Vorhinein hinterlegtes formales Gebiet ermöglicht, aber keinen realen Denkvollzug im wirklichen Leben darstellt.
Schon alleine aus diesem Grund wird ein Richterautomat nie möglich sein oder werden.
Da
künstliche IntelligenzMaschinenlernen immer unterkomplex ist, kann es nie selbständig Probleme der realen Welt lösen.
Da die von der künstlichen Intelligenz vom Maschinenlernen verwendeten Denkmodelle zudem immer unterkomplex zur realen juristischen Wirklichkeit sind, können sie – rein systemtheoretisch betrachtet – auch nie juristische Probleme akkurat Probleme lösen (Ashybs Law) – so wie bei Malen nach Zahlen nie ein echtes Kunstwerk entstehen wird.
Der Turing-Test⌗
Laut Adrian soll es möglich sein, «eine Theorie zu entwerfen, die erklärt, warum eine Maschine […] juristische Sprache so umfassend simulieren können müsste, dass ein Rechtsfall insgesamt entschieden werden kann.»
Eine Maschine kann alleine schon deshalb nie einen Rechtsfall lösen, weil sie nicht einmal in der Lage ist, einen solchen als solchen zu erkennen. Als Gegenstand kann ein Computer keine Probleme haben, also kann er auch nicht intelligent sein, so die überzeugende Argumentation von Markus Gabriel auf Basis der Annahme, dass Intelligenz die Fähigkeit ist, Probleme zu lösen.
Adrian verwechselt hier den Anschein von Fallösung mit echter Fallösung, also die künstliche Intelligenz als modellabhängige Landkarte mit dem realen rechtlichen «Gelände». Die Simulation der juristischen Sprache als statisches Substrat von etwas lebendig geistig Gedachtem hat mit dem zugrundeliegenden realen Denkvollzug so viel zu tun wie das Foto Ihres Lebensmenschen in der Geldtasche mit dem realen Menschen dahinter. (Wie Einstein angeblich über ein ihm gezeigtes Foto anmerkte: Aha, das ist also Ihre Frau, die ist aber wirklich sehr klein.)
Laut Adrian soll die Maschine dann mit dem Turing-Test dahingehend getestet werden, ob «der Text von einer Mehrheit von Juristen für sinnvoll erachtet wird». Dieser Test genügt ihm schon, um seine im Titel überhöhten Erlösungsversprechen zu begründen.
Inhaltlich (sic!) kann der Turing-Test das aber nicht leisten.
Mit einem erfolgreich absolvierten Turing-Test können Sie nur vermuten, dass ihr Gegenüber die Intelligenz einer echten Person haben könnte, nicht dass diese tatsächlich intelligent ist. Das ist ja genau das Problem des Turing-Tests, dass er von Intelligenz als Ausstattung von Lebewesen fürs Überleben abstrahiert und Intelligenz einseitig reduziert funktional verstehen möchte2.
Das ist ungefähr so, also ob bei Google Captchas3, die nichts anderes als einen Turing-Test darstellen, das Erkennen einer Brücke oder einer Verkehrsampel mit der Ingenieursintelligenz gleichgesetzt wird, die benötigt wird, um die Brücke oder die Verkehrsampel zu bauen:
Nur weil ein Text von Juristen mit einem hohen Anteil bekannter Phrasen als juristisch sinnvoll Text erachtet wird, sagt das nichts über seine Qualität und Geeignetheit im konkreten Fall aus.
Gerade moderne KI- Maschinenlern-Systeme scheitern zudem daran, ihre Aussagen begründen zu können. Eine solche Begründungsnotwendigkeit ist aber eine wesentliche Grundlage unseres Rechts- und Demokratieverständnisses.
Ohne Begründungskraft könnte ein Richterautomat, wie ihn Adrian sich wünscht, nur in einem totalitären System regelkonform eingesetzt werden.
Zusammenfassung⌗
Adrian hat mit viel Aufwand aber wenig Schlusskraft einen Ausweg gesucht, um «Legaltech» und der KI-Forschung einen theoretischen Unterbau zu liefern. Dieser Versuch scheiterte wegen offensichtlicher inhaltlicher und logischer Mängel.
Der schon in der Überschrift gesetzte Erwartungsdruck kontrastiert immer wieder eigenartig mit vernünftigen Anmerkungen. Der an vielen Stellen in Form der esoterisch aufgeladenen «Textquanten» durchkommende materialistische Digitalismus, der juristische Geistestätigkeit als solche ignoriert, lässt diese korrekten Schlüsse freilich in den Hintergrund treten.
Sein Aufsatz wirft darüberhinaus angesichts der sprunghaften und collageartigen «Argumentation», der axiomatischen Fixierung auf die Eingangsthese, die nicht weiter reflektiert oder begründet wird, grundlegende Fragen auf.
Es erstaunt sehr, dass so ein Aufsatz
- (1) überhaupt in einer renommierten juristischen Fachzeitschrift erscheinen konnte,
- (2) offenbar nicht weiter diskutiert oder thematisiert wurde,
- (3) nicht von der Rechtsgemeinschaft klar zurückgewiesen worden ist.
Das zeigt leider, wie schwach Rechtstheorie, Rechtsethik und Rechtsphilosophie als Geisteswissenschaften geworden sind:
Der Beitrag zeigt, in welchem Ausmass ein falsches digitales Rechtsbewusstein um sich gegriffen hat.
Es wirkt zumindest klärend, wenn sich klar die Unhaltbarkeit der beiden in der Überschrift geäusserten Thesen zeigt: Es kann auf Grund dieser Argumentationsketten sicher nie einen Richterautomaten geben und Semantik ist definitiv keine Illusion.
«more expensive, less accurate and slower»⌗
Um den berühmten NRC-Report aus 1966 (!) zu paraphrasieren, darf ich angesichts dieses Aufsatzes gerne und aus gutem Grund behaupten, dass ein Richterautomat teurer, ungenauer und langsamer als jede menschliche juristische Problemlösung wäre, wenn es denn einen solchen überhaupt gäbe («machine translation was more expensive, less accurate and slower than human translation»). Das Ziel war damals, für den Geheimdienst ein Übersetzungsprogramm aus dem Russischen zu entwickeln, und so die militärische Sicherheit zu erhöhen4.
Wenn Adrian andererseits meint, dass auf dieser Basis «der juristische Obersatz, also das Recht, von der Maschine und nicht durch einen menschlichen Richter „konstruiert“» werden soll, wird es richtig gruselig: Der Gedanke, dass für solche Forschungen öffentliche Gelder ausgegeben werden oder so ein Automat eines Tages tatsächlich normativ wirksam aufgestellt werden soll, ist einfach nur abstossend.
Dass Adrian eine LegalTech-Ausbildung leitet und dort mit hoher Wahrscheinlichkeit diese digitalistische Ideologie im Ausbildungskontext propagiert, wirkt gleichermassen besorgniserregend: Denn das Rechtssystem ist ohnehin schon über weite Strecken schon zu weit weg von den Rechtssubjekten, deren sozialen Alltag es regelt.
Für die geistige Freiheit juristischen Denkens⌗
Nach Gabriel kann Denken als Ausübung der Fähigkeit eines Lebewesens, verstanden werden, sich selbst in seiner Stellung zu bestimmen, und zwar auch in Bezug auf sein Denken.
Es geht also darum, die bestehende Kapazität der Menschen im Rechtssystem juristisch denken zu können, auch im Hinblick auf deren Ressourcen und Ausstattungen, zu stärken, nicht es weiter zu technisieren und damit unmenschlicher und entrückter zu machen.
Es wäre höchste Zeit, dass sich die Rechtsinformatik als Handlungswissenschaft den gesellschaftlichen Auswirkungen der Digitalisierung stellt und sich auf die nachhaltige Unterstützung von juristischen Denktätigkeiten zur Problemlösung und Theorieentwicklung fokussiert.
Um mit Steve Jobs zu sprechen:
Rechtsinformatische Digitalisierung als «Fahrrad für Juristen», nicht als ideologischer Digitalismus.
Epilog⌗
Dieser bemerkenswerte Aufsatz von Adrian stellt in eigenartiger Weise eine Ausprägung der Thesen dar, die er vertritt:
-
Er ist nicht nur realitätsfern, er ist überhaupt mit der Realität nicht verbunden (so wie er das von der Sprache behauptet). Weder mit der realen der KI-Forschung seit den 1960er Jahren, mit dem Stand der Computerlinguistik noch mit zeitmässen (rechts-)philosophischen Theorien der geistigen Gegenwart oder Vergangenheit.
-
Wenn Adrian Peirce nutzt, um daraus die Unmöglichkeit von Semantik abzuleiten und damit semiotische Konzepte einfach ins Gegenteil verdreht und verkennt, wirkt die Argumentation tatsächlich inhaltsfrei.
-
Adrian vermischt verschiedene wissenschaftliche Ansätze oberflächlich zu einem bedeutungsarmen Sammelsurium, bei dem man fast an die berühmten tippenden Affen denken muss, die mit einer ganz geringen Wahrscheinlichkeit auch einmal ein sinnvolles Buch erzeugen – oder zumindest eines, das man auf den ersten Blick dafür halten könnte.
-
Der Aufsatz würde den Turingtest bestehen: Auf den ersten Blick ist es ein akademisch ernstzunehmender Aufsatz. Man hält ihn für wissenschaftlich. Er könnte von einem Menschen geschrieben sein, der sich mit Rechtstheorie, Philosophie und Wissenschaftsttheorie – mit der «Rechtsmaterie» auskennt.
Dass der Beitrag überhaupt in einem rechtswissenschaftlichen Journal erscheinen konnte, deutet auf eine tiefe Krise des Rechts hin:
Das Recht versteht die Welt offenbar nicht mehr.
Es ist in einem Paradigmenwechsel verfangen, den es selbst noch gar nicht richtig wahrnimmt. Das Rechtssystem ist nicht mehr national, hierarchisch, normativ tonangebend. Das Digitale und die Globalisierung haben ihm stark zugesetzt. Es gibt immer mehr rechtsfreie Räume und für das Recht schwer einordenbare Phänomene wie digitale Währungen oder Algorithmen.
Dem Recht ist deshalb jedes Mittel recht, und erst recht die modernen digitalen – um nur am Leben zu bleiben – offenbar bis hin zur freiwilligen Selbstaufgabe. Die Selbstachtung der Rechtsphilosophie und der juristische Selbstwert haben sich selbst aufgegeben. Das Recht hat abgedankt. Es ist nicht einmal in der Lage seine eigene «Verfahrenheit» zu erkennen, geschweige denn den eigenen Paradigmenwechsel zu orchestrieren, «sich selbst in seiner Stellung zu bestimmen und zwar auch in Bezug auf sein Denken», wie Gabriel formuliert.
In diese Notlage entfaltet sich der US-amerikanische Digitalismus, der transhumanisch den Menschen vom Menschen erlösen möchte. Auf dieser Erlösungsideologie segelt letztendlich dieser Artikel: Er gibt – freilich vollkommen unberechtigte – Hoffnung, dass das Recht auch im digitalen eine Funktion haben kann. Wenn nur endlich der erste Schritt gesetzt ist und geforscht wird, darf es in Zukunft Rechtsautomaten zuarbeiten! Ohne rechtstheoretisches Fundament, mit einer Rechtsinformatik die sich auf selbst auf Rechtsdogmatik beschränkt hat und selbstreferentiell nie über ihre ersten Forschungen hinausgekommen ist, ohne eine Rechtsphilosophie, die halbwegs auf der Höhe der Zeit ist, fehlt ihr jedes Kriterium, um so einen Beitrag wie diesen von Adrian zu enttarnen.
Während Firmen wie IBM oder GE bei ähnlich gelagerten Annahmen inzwischen Milliardenverluste schultern mussten und sich an den Rand ihrer wirtschaftlichen Überlebensfähigkeit brachten5, sind akademische Institutionen in Deutschland offenbar geistig frei finanziert Räume für solche Fakekonzepte.
Post Scriptum⌗
Dass es auch anders geht, und zwar auch in Deutschland, beweist Professor Markus Gabriel6 mit seinem Forschungszentrum «Center for Science and Thought» für KI in Bonn. Er hat die Klarheit und interdisziplinäre Kompetenz, um tatsächlich vorne dran zu sein an der Erforschung von Konzepten der künstlichen Intelligenz, die ihren Namen auch verdienen. Seinen Ausführungen verdanke ich die notwendige Klarheit um die Problematik des Artikels näher zu begutachten und zu analysieren, wobei sämtliche möglichen Fehler und Missverständnisse seiner Ausführungen natürlich meine eigenen bleiben.
-
Wenn sie sich einen Finger einklemmen und von einem nahen Menschen Mitgefühl erhalten sind sowohl die Realität als auch die Kommunikation real und nicht simuliert. ↩︎
-
Turing, Alan (1950): Computing Machinery and Intelligence, Mind 49: 433-460. ↩︎
-
Captcha’s sind Testfragen in Online-Formularen, die prüfen sollen, ob ein Mensch tatsächlich aktiv eine valide Eingabe tätigt oder ob es sich um einen Bot handelt, also um ein Programm, das vermutlich mit böser Absicht das Formular manipuliert. ↩︎
-
Dass Argument, dass eben diese Aussage falsch ist, weil es inzwischen viel leistungsfähigere Übersetzungsprogramme gäbe, ist zwar richtig, zeigt aber genau das Problem, wie sich an einem kleinen Beispiel zeigt:
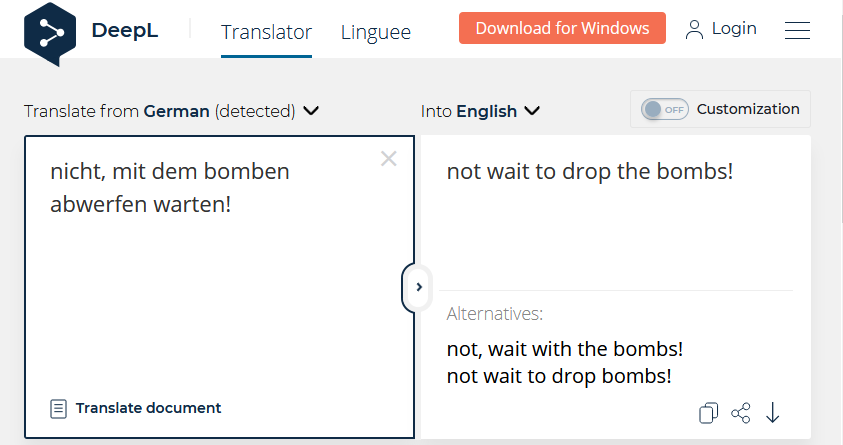 Versetzen wir uns gedanklich in den kalten Krieg und nehmen wir an, die Amerikaner haben den russischen Satz: “nicht, mit dem bomben abwerfen warten!” abgefangen. Sie geben dies heute in die mit einiger Wahrscheinlichkeit beste öffentlich verfügbare Übersetzungsengine DeepL ein und erhalten: “not wait to drop the bombs!”. Nicht unwahrscheinlich, dass sie sich dann verteidigen möchten und dass ein Krieg beginnt, weil es ein Computer falsch übersetzt hatte. Man beachte die Tragik der angezeigten Alternative rechts unten, die es richtig übersetzen würde und das Gegenteil ausdrückt. Hier zeigt sich, dass Machine Learning, Legal- und Fintech selbst bei weiteren Verbesserungen nie Ratgeber sein können, sondern nur «Rategeber». ↩︎
Versetzen wir uns gedanklich in den kalten Krieg und nehmen wir an, die Amerikaner haben den russischen Satz: “nicht, mit dem bomben abwerfen warten!” abgefangen. Sie geben dies heute in die mit einiger Wahrscheinlichkeit beste öffentlich verfügbare Übersetzungsengine DeepL ein und erhalten: “not wait to drop the bombs!”. Nicht unwahrscheinlich, dass sie sich dann verteidigen möchten und dass ein Krieg beginnt, weil es ein Computer falsch übersetzt hatte. Man beachte die Tragik der angezeigten Alternative rechts unten, die es richtig übersetzen würde und das Gegenteil ausdrückt. Hier zeigt sich, dass Machine Learning, Legal- und Fintech selbst bei weiteren Verbesserungen nie Ratgeber sein können, sondern nur «Rategeber». ↩︎ -
Ebenhoch, Peter (2020): Die Zipperlein des Dr. Watson. Dumm, wie Digitalisierung scheitern kann. ↩︎
-
Gabriel, Markus (2018): KI als Denkmodell, Petersberger Gespräche ↩︎